
Savonia Article Pro: Monitoring Stable Soundscapes: AI Model Selection and Development Plans
Savonia Article Pro is a collection of multidisciplinary Savonia expertise on various topics.
This work is licensed under CC BY-SA 4.0![]()
![]()
![]()
1. Introduction
In the second pilot phase of our project, we focus on detecting abnormal sound events within horse stables through advanced sound analysis using machine learning (ML). This pilot aims to alert caretakers promptly, especially during times when horses are unattended, such as nighttime, thus significantly improving animal welfare.
2. Background and Motivation
Horses frequently face health or safety issues, such as becoming trapped or sustaining injuries, that often go unnoticed, especially overnight. Early intervention is critical in mitigating risks and preventing serious complications.
In this project we are concentrating on audio event classification. This narrower focus maximizes the efficiency of our development team, as audio labeling generally demands fewer resources and less time compared to video labeling and we can leverage specialized ML models that excel in audio processing tasks. Nevertheless, we continue using video recordings to support and validate our audio annotations.
Due to the infrequent and unpredictable nature of abnormal stable events, conventional supervised learning methods become challenging, given the limited availability of training examples. Therefore, our approach emphasizes methods capable of effectively learning from predominantly normal ambient sound data or very sparse data.
3. Technical Overview and Background
Recent research in sound anomaly detection suggests several promising ML approaches suitable for our context. Two main categories include anomaly detection techniques, notably autoencoders and supervised sound classifiers, particularly convolutional neural networks (CNNs). A decent overview of audio classification in deep learning was provided by Kahlid et al. (Khalid et al. 2023).
3.1 Anomaly Detectors: Autoencoders
Autoencoders are well-established in anomaly detection tasks, where they learn to reconstruct normal soundscapes from extensive ambient audio data. When presented with abnormal sound events, autoencoders produce notably larger reconstruction errors, effectively signaling anomalies. Such methods have shown significant success in predictive maintenance by enabling early fault detection in industrial machinery (Koizumi et al., 2018). However, autoencoders generally require periodic retraining due to their limited generalization when environmental conditions, such as seasonal changes, vary. So how effectively they can be used in a stable environment has to be studied.
3.2 Sound Classification: Pre‑trained CNN Features + Lightweight Classifier
We use a two‑step approach that balances power and practicality:
1.) Feature extraction with PANNs (a pre‑trained CNN).
– PANNs, more specifically the CNN14 model, has already been trained on millions of everyday sounds in Google’s AudioSet. (Kong et al. 2020)
– For every 2‑second audio clip it produces a compact 2 048‑number “fingerprint” (called an embedding) that captures the clip’s pitch, rhythm and texture.
– Because this CNN is frozen (we don’t change its weights), we get state‑of‑the‑art audio features “out of the box” without heavy training.
2.) Task‑specific classifier with a few dense layers.
– On top of the embeddings, we stack a small feed‑forward network (three dense layers plus dropout).
– This network learns to recognise patterns like kick vs non‑kick (and, later, other stable events) using far less data and compute than training a whole CNN from scratch.
– Training is quick, minutes rather than hours, because only about one million parameters are updated.
This transfer‑learning design gives us the best of both worlds: rich representations from a powerful CNN, and a nimble classifier that can be retrained or expanded as we collect new labelled sounds.
4. Technical Resolution – Our Development Plan
4.1 Challenges
We currently face two primary challenges:
1. Ambiguity in Defining Abnormal Events: Clear definitions of what constitutes an “abnormal” sound in stable environments are currently lacking, complicating accurate labeling.
2. Scarcity of Training Data: Initially, we will have limited or no recordings representing abnormal events for model training.
4.2 Strategic Plan
To overcome these challenges, we propose a hybrid approach integrating anomaly detection and supervised classification methods:
– Broad Initial Labeling: Initial labeling efforts will identify common stable sound sources and their typical acoustic features, establishing a baseline for normal ambient conditions.
– Anomaly Detection Pipeline: An autoencoder-based anomaly detection model will be trained initially on normal soundscapes, facilitating early identification of potential abnormal events. These segments will then serve as preliminary labeling candidates.
– Supervised Classifier Integration: In parallel, we will train a compact MLP classifier that takes the PANNs embeddings as input. Candidate abnormal segments identified by the autoencoder serve as seed examples; human annotators then verify and refine these labels. The resulting dataset is used to iteratively fine‑tune the classifier, improving its precision while keeping annotation costs manageable.
– Integrated Hybrid System: Initially, the anomaly detector and the supervised classifier will operate simultaneously. Over time, we will implement a voting or cascading strategy that leverages the autoencoder’s broad anomaly detection capabilities and the classifier’s precision in identifying specific abnormal events as described in Figure 1.
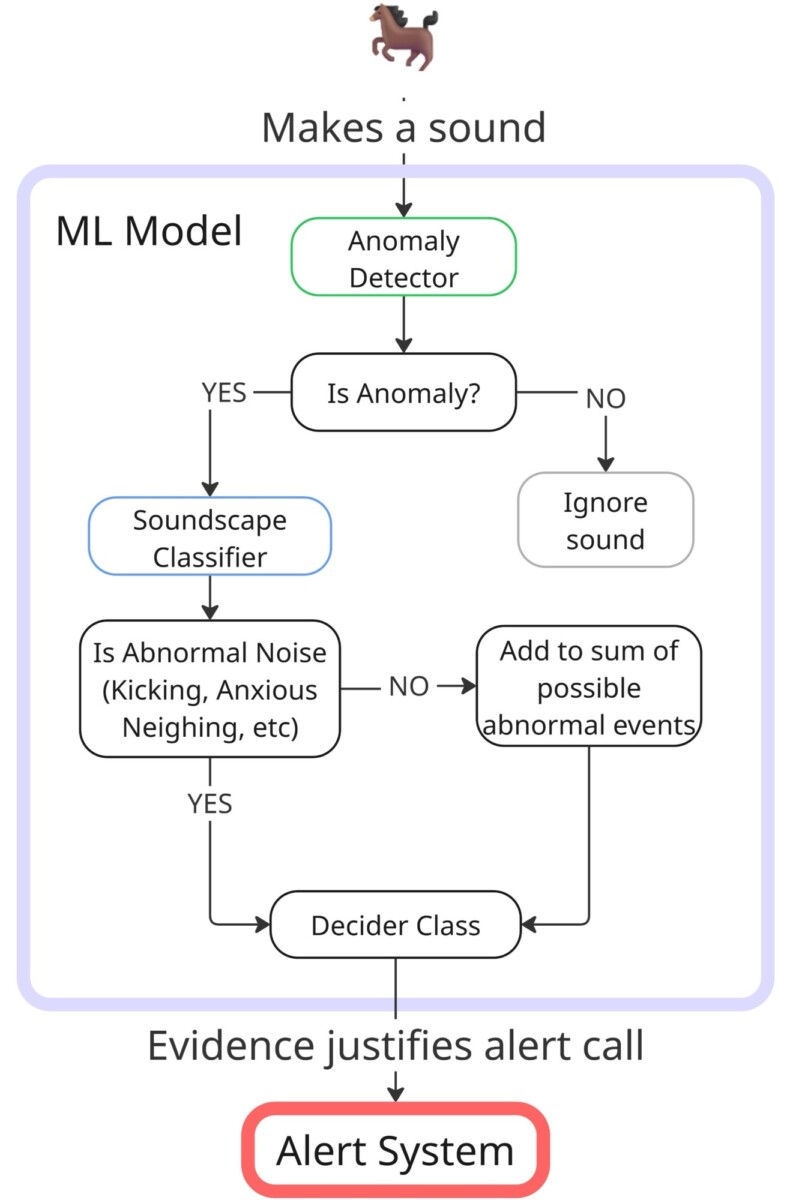
5. Conclusion
Through this combination of autoencoder-based anomaly detection and carefully curated supervised classification, our pilot aims to address the challenges of stable soundscape monitoring. The expected outcome is a reliable and scalable AI-driven model to work as a backend for our stable alert app, providing timely and accurate alerts to caretakers.
Authors:
Johannes Geisler, RDI Specialist, DigiCenter,
Osman Torunoglu, RDI Specialist, DigiCenter,
Finlay Hare, RDI project worker, DigiCenter,
Aki Happonen, Digital Development Manager, DigiCenter,
Heli Suomala, Project Manager and Expert, Finnish Horse Information Centre
References:
Zaman, Khalid, et al. “A survey of audio classification using deep learning.” IEEE access 11 (2023): 106620-106649.
Koizumi, Yuma, et al. “Unsupervised detection of anomalous sound based on deep learning and the neyman–pearson lemma.” IEEE/ACM Transactions on Audio, Speech, and Language Processing 27.1 (2018): 212-224.
Kong, Qiuqiang, et al. “Panns: Large-scale pretrained audio neural networks for audio pattern recognition.” IEEE/ACM Transactions on Audio, Speech, and Language Processing 28 (2020): 2880-2894.

* This work is part of the “Tekoälyä talleille” project at Savonia University of Applied Sciences.